Comparing Databricks Delta Live Tables And Snowflake Dynamic Tables

The Databricks vs. Snowflake Battle Continues
Building and managing data pipelines can be complex and time-consuming, particularly when dealing with evolving datasets, frequent updates, and ensuring reliability at scale. Traditional methods often require extensive manual effort to maintain - such as MERGE statements, keeping track of which data was loaded last. This is where declarative programming comes into play. By allowing developers to define what they want instead of how to achieve it, declarative pipelines simplify the pipeline creation and management process.
In this post, we’ll explore how Databricks Delta Live Tables (DLT) and Snowflake Dynamic Tables serve as modern, automated solutions for pipeline development. While we won’t dive into the technical specifics of each framework, we’ll focus on the user experience, pipeline management, and observability features that distinguish them.
- 💰 Use Case: Fictional Sales Data
- 🏗️ Creating Data Pipelines
- 🤷 Comparison
- 🎯 Choosing Between Databricks Delta Live Tables and Snowflake Dynamic Tables
- 🤔 Final thoughts
💰 Use Case: Fictional Sales Data
To compare DLT and Snowflake Dynamic Tables in action, we’ll work with a fictional sales dataset. The relevant data generation code and pipelines for both platforms are available in this repository.
Data overview
We’ll base our comparison on a set of four related tables representing sales data. Here’s a quick summary of the tables and their relationships, depicted in the diagram below:
- Orders: A fact table containing details of customer purchases.
- Transactions: Metadata about the purchase, including transaction status (successful or failed).
- Customers: A dimension table with customer information, linked to the
Orderstable. - Products: A dimension table for products, also linked to
Orders.
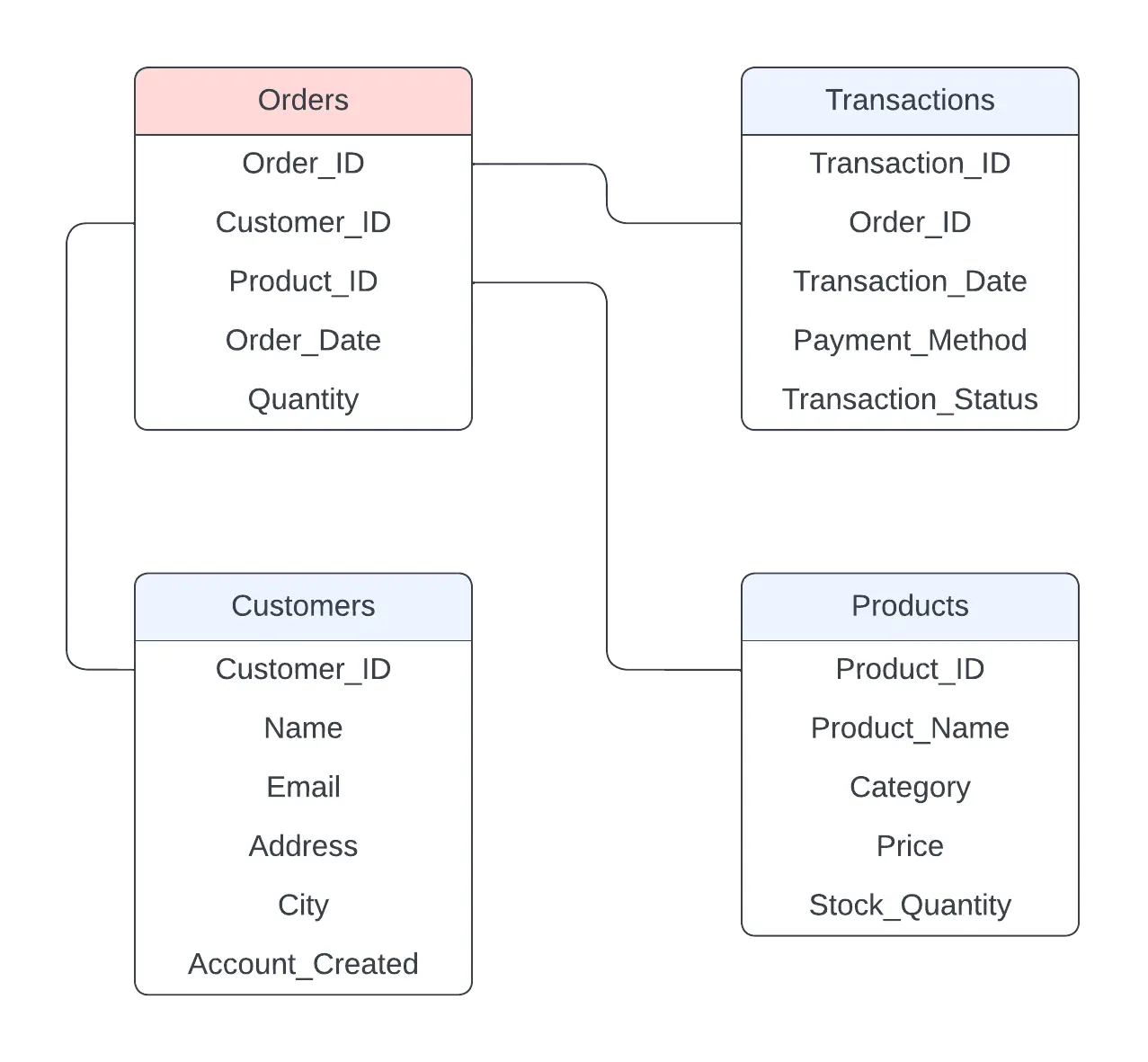 Identity-relation diagram of the four base tables
Identity-relation diagram of the four base tables
🏗️ Creating Data Pipelines
Using the data structure outlined above, we’ll now create simple pipelines with both DLT and Snowflake Dynamic Tables to see how they approach similar tasks. The pipelines will carry out three primary steps:
- Filter the
Orderstable using theTransactionstable, keeping only successful transactions. - Generate a summary of total sales per customer, including the number of orders and total amount spent.
- Create a report on sales by product category, showing the number of sales and total revenue for each product.
DLT Pipeline In Databricks
In Delta Live Tables, pipelines can be created using either SQL or Python. For simplicity, let’s look at the SQL approach, which resembles a CTAS (CREATE TABLE AS SELECT) statement.
To filter the Orders table by successful transactions (step 1), the following SQL query can be used:
CREATE OR REFRESH STREAMING LIVE TABLE successful_orders
AS
SELECT
o.order_id,
o.customer_id,
o.product_id,
o.order_date,
o.quantity
FROM STREAM <database>.<schema>.orders o
JOIN <database>.<schema>.transactions t
ON o.order_id = t.order_id
WHERE t.transaction_status = 'Success';
While Python can also be used to define pipelines in DLT, for the sake of comparison with Snowflake Dynamic Tables—which only support SQL—we’ll focus on SQL here. For more detailed examples using both SQL and Python, refer to the DLT folder in the repository.
Dynamic Tables In Snowflake
Snowflake’s Dynamic Tables currently only support SQL for pipeline creation, similar to DLT’s SQL-based pipelines. Here, too, a CTAS-like statement is used to filter the Orders table based on successful transactions:
CREATE OR REPLACE DYNAMIC TABLE successful_orders
LAG='DOWNSTREAM'
WAREHOUSE=<warehouse>
AS
SELECT
o.order_id,
o.customer_id,
o.product_id,
o.order_date,
o.quantity
FROM <database>.<schema>.orders o
JOIN <database>.<schema>.transactions t
ON o.order_id = t.order_id
WHERE t.transaction_status = 'Success';
As we begin to explore the code, some differences in syntax and functionality between DLT and Dynamic Tables already become apparent. Let’s dive deeper into how these platforms differ in terms of features and user experience.
🤷 Comparison
Let’s dive deeper into how DLT and Dynamic Tables offer unique features - and how similar they are. The results of this section are summarized in the table below.
| Feature | Databricks Delta Live Tables (DLT) | Snowflake Dynamic Tables |
|---|---|---|
| Underlying Technology | Built on Delta Lake, uses Apache Spark for data processing | Native feature of Snowflake, uses Snowflake’s virtual warehouses |
| Compute | Spark clusters, configurable parameters, optional serverless option (costly), one cluster for the entire pipeline | Virtual warehouses (T-shirt sizes), can select different warehouses per table |
| Streaming vs Batch | Support for both streaming and batch processing | Currently focused on batch processing, no streaming support (yet) |
| User Experience | More setup required for complex use cases, supports both SQL and Python | Simpler, SQL-only approach, easier for users familiar with Snowflake SQL |
| Pipeline Scheduling & Orchestration | Exact control over pipeline execution, part of larger pipelines (via Databricks Jobs) | Uses target lag for table freshness, no control over exact execution timing, not part of larger pipeline orchestration |
| Data Quality | Supports row-level data quality rules (expectations) | No built-in data quality enforcement |
| Monitoring & Visibility | DAG visualization, tracks last pipeline run time | DAG visualization, table freshness tracking |
Summary of the comparison between DLT and Dynamic Tables
Underlying Technology
Delta Live Tables
DLT operates on top of Databricks’ Delta Lake. DLT is integrated into the Databricks platform, where all data transformations run on Spark clusters. Using Spark, DLT is able to handle both batch and streaming data. Users can configure these Spark clusters with many parameters, such as cluster size, memory, and compute resources. There’s also a serverless option, which simplifies infrastructure management but comes at a higher cost. In DLT, a single cluster is used to process the entire pipeline.
Dynamic Tables
Dynamic Tables are a native feature within the Snowflake environment. They are tightly integrated with Snowflake’s architecture, and all the transformations happen inside Snowflake’s compute engine. Dynamic Tables rely on Snowflake’s virtual warehouses, which can be selected for each table independently. This T-shirt size model allows users to adjust compute resources based on the specific workload, offering flexibility without needing to manage clusters. Unlike DLT, each Dynamic Table could use a different warehouse - even within the same pipeline.
Data Ingestion
Delta Live Tables
DLT offers a more streamlined solution with its Auto Loader feature. Autoloader is a powerful tool that simplifies the ingestion of data from cloud storage into Delta Lake. It automatically detects new files as they arrive and efficiently loads these. Autoloader’s ability to handle schema evolution and automatically scale to handle large volumes of data makes it ideal for handling both batch and streaming ingestion with minimal setup.
Dynamic Tables
In contrast, Snowflake Dynamic Tables does not provide a built-in equivalent to Autoloader. To ingest data into a Dynamic Table, you would typically need to set up a Stream manually, which requires more configuration. Streams in Snowflake track changes in the source data, allowing the Dynamic Table to be updated based on new records or changes. However, this setup is less automated compared to DLT’s Autoloader and requires additional steps to manage both the Stream and the pipeline effectively.
Streaming vs. Batch Processing
Delta Live Tables
When it comes to data processing modes, DLT shines with its support for both streaming and batch processing. It enables transitions between real-time data streams and scheduled batch jobs using minor code changes. This provides flexibility to build more complex, time-sensitive pipelines.
Dynamic Tables
In contrast, Dynamic Tables in Snowflake are currently focused on batch processing. This is sufficient for many use case - particularly in data warehousing. However, it does limit scenarios that require real-time data updates. Streaming capabilities may be enhanced in future updates, but for now, batch is the primary focus.
User Experience & Code Flexibility
Delta Live Tables
From a user experience perspective, DLT offers flexibility but at the potential cost of complexity. Users can write pipelines in either SQL or Python, giving more control over how pipelines are written and maintained. However, the ability to code in Python (in addition to SQL) might lead to more intricate setups, especially for users working on complex use cases. Configuring Spark clusters, tuning parameters, and handling additional options can add to the learning curve, but also offer greater flexibility for those familiar with Spark.
Dynamic Tables
Snowflake Dynamic Tables simplifies the user experience by focusing solely on SQL for defining pipelines. This makes the learning curve smoother, especially for users who are already familiar with Snowflake’s SQL-based approach. There is no need to manage complex cluster settings or select between different coding languages, which provides an experience that may appeal to users seeking simplicity.
Freshness, Scheduling, and Orchestration
Delta Live Tables
DLT offers fine-grained control over pipeline execution, allowing users to define exactly when a pipeline should run. DLT pipelines can be integrated into larger workflows using Databricks Jobs, allowing them to be part of end-to-end data processing orchestrations. This level of scheduling control is particularly valuable for managing complex data workflows that require precision timing and tight orchestration.
Dynamic Tables
In comparison, Dynamic Tables use a target lag approach, which defines how far behind a dynamic table can lag relative to updates in the source table. This ensures a certain level of freshness but doesn’t provide exact control over when transformations occur. As of now, Dynamic Tables cannot be integrated into larger orchestrated workflows, as they are not part of Snowflake’s broader task scheduling framework.
Data Quality
Delta Live Tables
DLT offers built-in support for data quality enforcement with its expectations feature. Users can define row-level data quality rules, ensuring that specific conditions are met before data is processed or moved forward in the pipeline. This feature helps ensure data accuracy and reliability within the pipeline itself.
Dynamic Tables
In contrast, Snowflake Dynamic Tables do not currently provide built-in mechanisms for enforcing data quality rules. While Snowflake offers other features outside Dynamic Tables that can support data validation, there’s no direct equivalent to DLT’s row-level expectations.
Monitoring and Visibility
Both platforms offer decent monitoring features, but with some key differences.
Delta Live Tables
Users can easily monitor their pipelines using a DAG (Directed Acyclic Graph) visualization, which shows the flow of data transformations and dependencies. Additionally, users can track the last time the pipeline was run, making it easier to ensure timely updates. These monitoring tools are integrated into the Databricks interface, offering a clear view of pipeline performance and data flow. This visualization does not include the base tables upstream of the DLT tables.
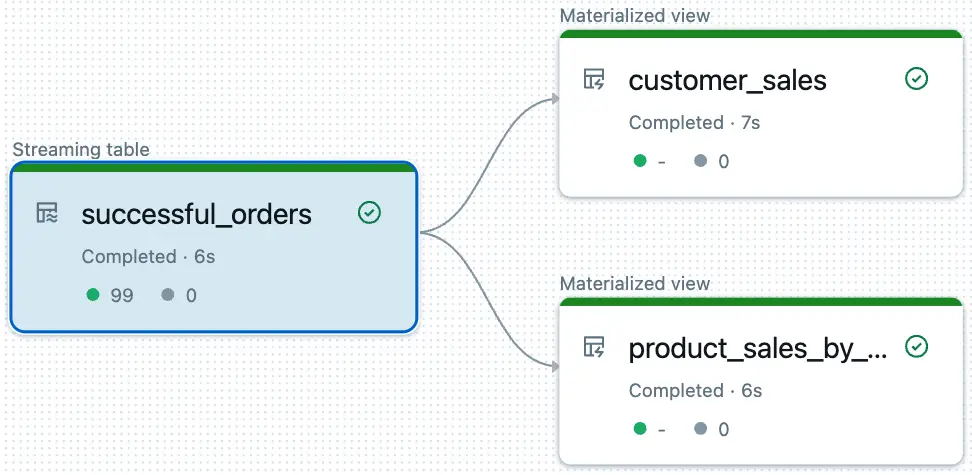 DAG visualization in DLT
DAG visualization in DLT
Dynamic Tables
Similarly, Dynamic Tables provide DAG visualizations that show how transformations are connected. Snowflake also tracks table freshness, providing insights into how up-to-date a table is relative to its base data. However, there’s less granularity in terms of monitoring the exact execution times and pipeline run history compared to DLT. A nice feature here is that this visualization also includes the upstream base tables.
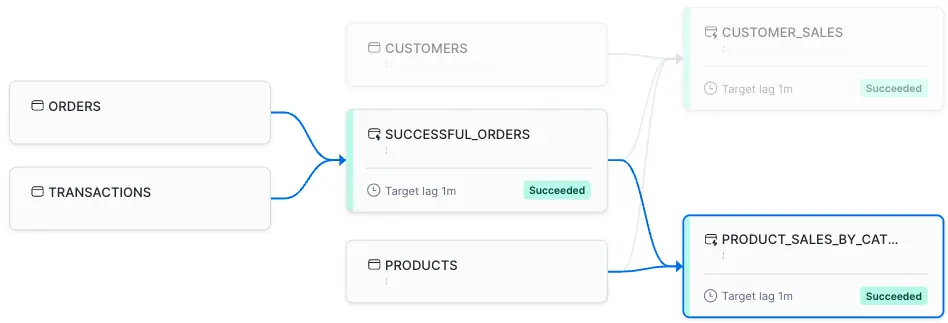 DAG visualization in Dynamic Tables
DAG visualization in Dynamic Tables
🎯 Choosing Between Databricks Delta Live Tables and Snowflake Dynamic Tables
When deciding between Delta Live Tables (DLT) on Databricks and Dynamic Tables on Snowflake, it’s important to remember that neither tool alone is likely to make a user of one platform switch to the other. Instead, the choice should be driven by your specific use case, the complexity of your data pipelines, and the platform you’re already using.
When to Choose Databricks Delta Live Tables (DLT)
DLT is a strong option for users who need robust, real-time streaming capabilities in their data pipelines - DLT’s integration with Apache Spark makes it the ideal choice. Its ability to handle both streaming and batch data within the same platform is a significant advantage for organizations needing flexibility across different types of workloads.
For batch processing scenarios, DLT also excels when pipeline scheduling and orchestration are critical. The ability to schedule and control exactly when pipelines run, and to integrate them into larger workflows (using Databricks Jobs), makes DLT a good fit for complex data pipelines that require precise timing and execution control.
Who should choose DLT?
- Users with advanced technical skills who are comfortable working with both SQL and Python.
- Teams with streaming data use cases that need both real-time and batch processing.
- Developers who prefer the flexibility of PySpark for writing more complex queries or for reusing code across multiple tables in their pipelines.
When to Choose Snowflake Dynamic Tables
On the other hand, Snowflake Dynamic Tables are the right choice for users looking for a simpler, more straightforward solution for batch data pipelines within the Snowflake environment. If your use case doesn’t require the complexity of streaming data or intricate orchestration across multiple jobs, Dynamic Tables provide a user-friendly experience with minimal setup. They are particularly appealing for those who prefer working in SQL, as all pipeline logic is written in a familiar syntax without the need to manage Spark clusters or tune complex parameters.
Who should choose Dynamic Tables?
- Users who prioritize ease of setup and prefer to avoid the added complexity of cluster configuration.
- Teams focused on batch data processing within the Snowflake ecosystem, where pipelines need to be simple and manageable.
- Data teams that mainly use SQL for data transformations and do not need the flexibility offered by PySpark or the advanced features of Spark clusters.
Key Considerations: Cost and Specific Needs
Ultimately, the decision between DLT and Dynamic Tables should also factor in cost considerations. While DLT offers powerful features such as streaming support and flexible pipeline scheduling, it also requires managing Spark clusters, which can be more costly, particularly if opting for the serverless option. Snowflake, with its T-shirt-sized virtual warehouses, allows for more granular control over resource allocation, but lacks the depth of customization that DLT provides.
🤔 Final thoughts
Both Databricks Delta Live Tables and Snowflake Dynamic Tables represent significant advancements in creating and automating data pipelines. DLT shines with its ability to handle real-time data, while Dynamic Tables offer a user-friendly approach for batch data pipelines within Snowflake.