For Each In Databricks Workflows

One For Each, Each For All!
It’s finally here! The long-awaited feature of for loops is available in Databricks Workflows. This allows you to neatly create multiple tasks based on a list of input values. I finally had time to check it out and have a go at it myself, so let’s see it in action!
Running A Parameterized Notebook
What are we trying to achieve exactly? As an example, we want to run a parameterized notebook in Databricks. This notebook takes a single parameter country and prints it:
country = dbutils.widgets.get("country")
print(country)
Simple stuff. How can we use Workflows to call the above code for multiple countries?
💾 Level 0: Back In the Olden Days
Previously, we had to manually create separate tasks for these. Assuming we have three different countries we want to run this for, the job would have three tasks.
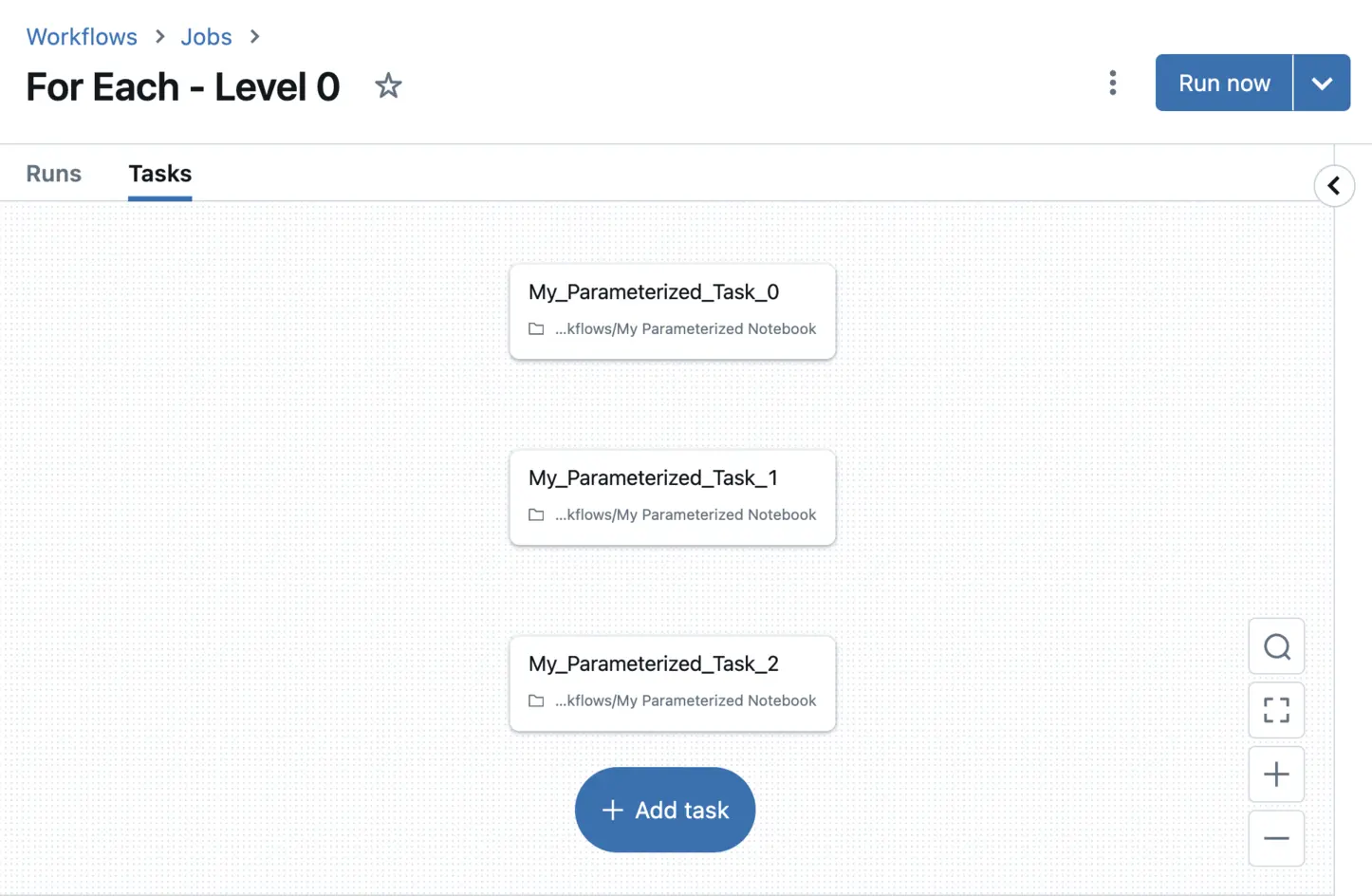 Databricks Job with three manually created tasks, each using a different value for the same
Databricks Job with three manually created tasks, each using a different value for the same country parameter
This works just fine. Going into the result of the first task, we see it successfully printed the input country parameter.
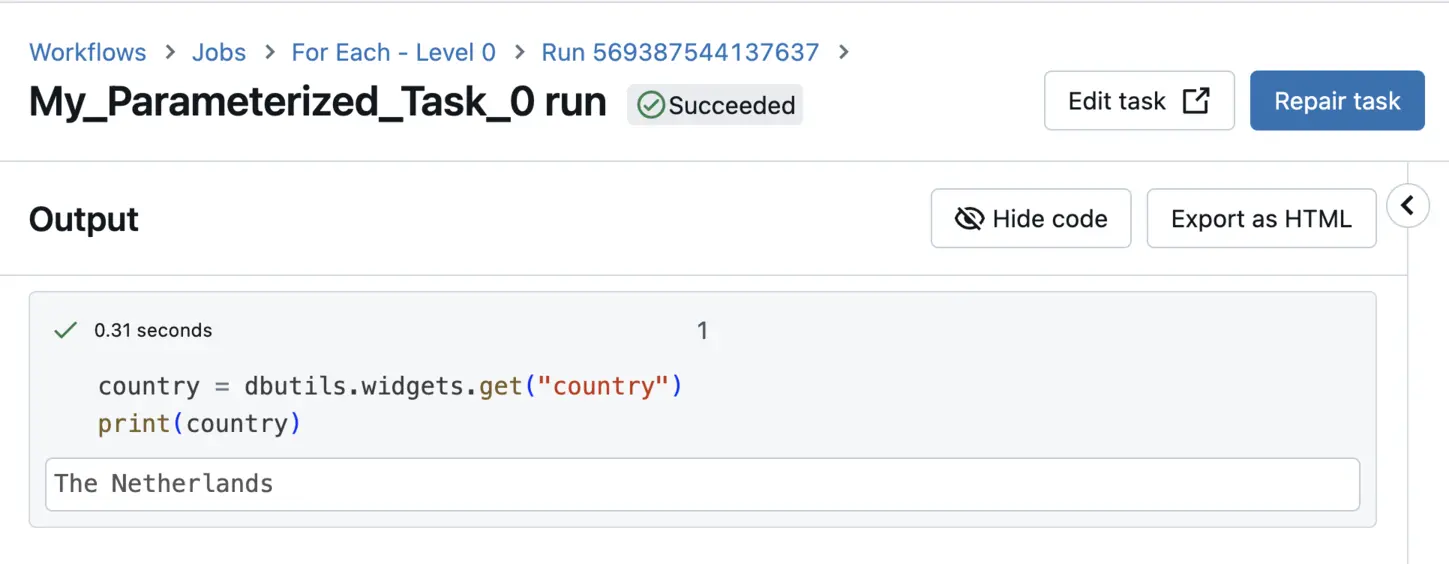 Output of a task running a parameterized notebook
Output of a task running a parameterized notebook
Manually creating three instances of the same task is a bad practice, and cumbersome at best. Altering anything about this task would require us to change all three tasks manually. In addition, managing dependencies between tasks becomes more difficult.
How can we improve this?
⌨️ Level 1: For Each, But With Hardcoded Task Values
Instead of manually creating these tasks as in Level 0, we want to use the newly introduced For Each task type. This can be achieved using a two-step approach, where we create a parent task and a child task to execute multiple times.
First, create a task of the type For each. Note how for the Inputs field, I manually specify a JSON like object to loop over. This will make sure our notebook is run three times, as I’ve listed three input values here.
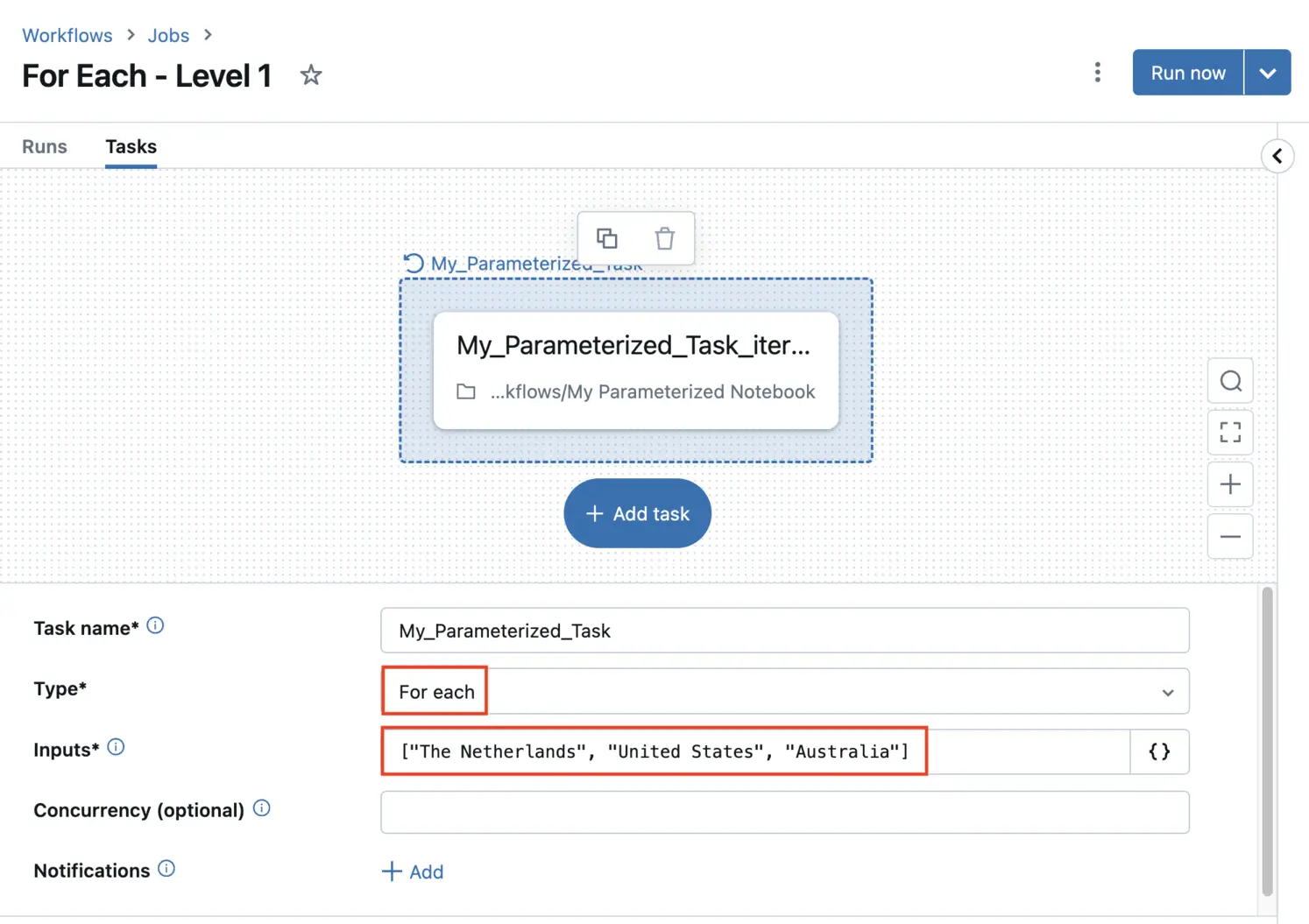 Defining a For Each task using hardcoded input values
Defining a For Each task using hardcoded input values
Next, within this parent task, define another child task to execute. Note how in the UI the inner (child) task is now selected.
This child task will be executed once for each element in the Inputs field. Which parameterized notebook to use is specified in the child task. More importantly, we also specify the parameter to pass to the notebook. Here we use the {{ input }} notation to indicate the current element of our input array - taken from the Inputs option listed in the parent task.
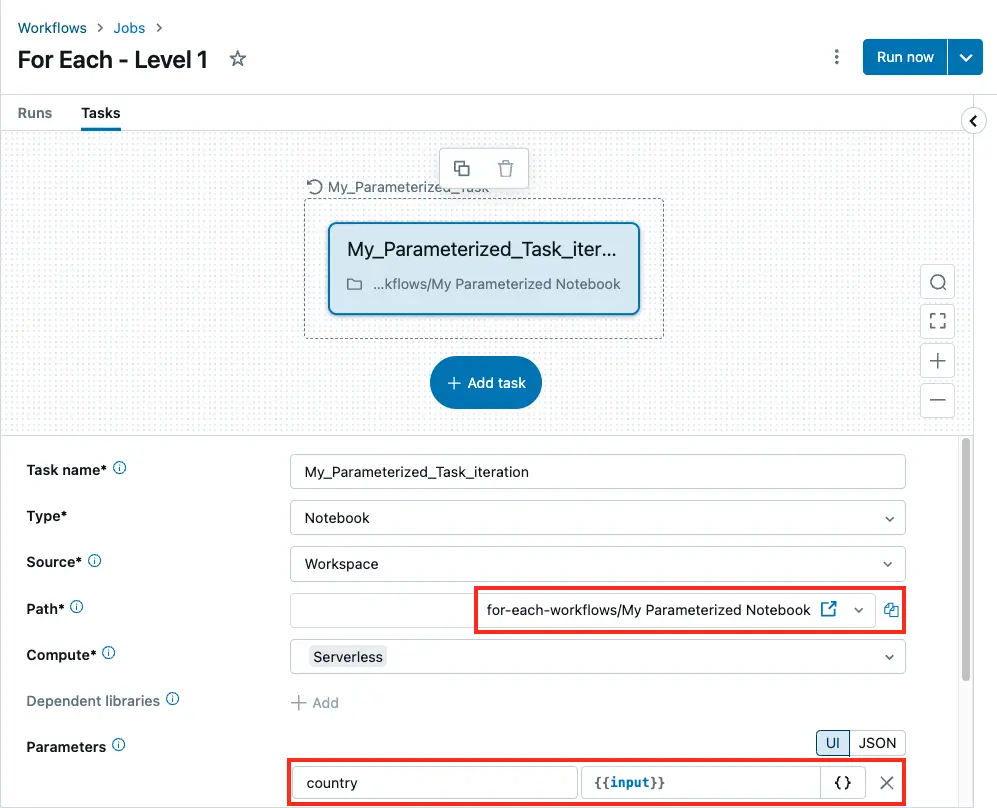 Child task of a For Each parent. The same
Child task of a For Each parent. The same country parameter is used
This creates a job with three input parameters that we can run. Running it indeed shows three tasks - as expected.
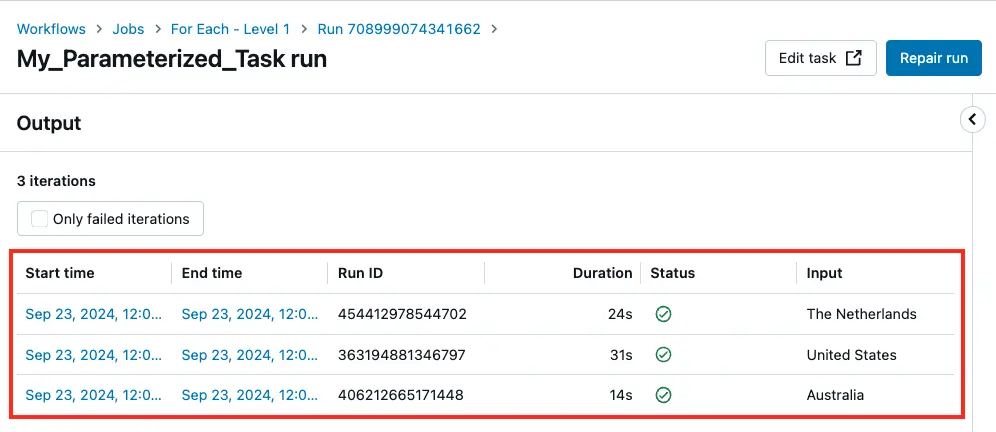 Three child tasks run as part of a For Each parent task
Three child tasks run as part of a For Each parent task
Just as with any other type of task, it’s possible to go into the output of each task individually to see the expected print statements being executed.
🪄 Level 2: Generate Task Values Programatically
In the above example, we hardcoded the values for the Inputs field using three country names. While this works, it is only a small improvement over manually creating three tasks - everything’s still hardcoded.
Instead, we should define the parameters elsewhere, making the job more flexible. To achieve this, create another notebook setting so-called task values, which can then be utilized by the For Each task.
values = ["The Netherlands", "United States", "Australia"]
dbutils.jobs.taskValues.set(key="countries", value=values)
The job below now looks almost identical to the one created for Level 1, except that we have added an extra step at the beginning. This extra step sets the task values. In addition, the value for the Inputs option is also slightly different. We now use the countries task values set in the Set_Parameters task. Referencing each element in the inner child task remains the same - i.e.,, {{ input }}.
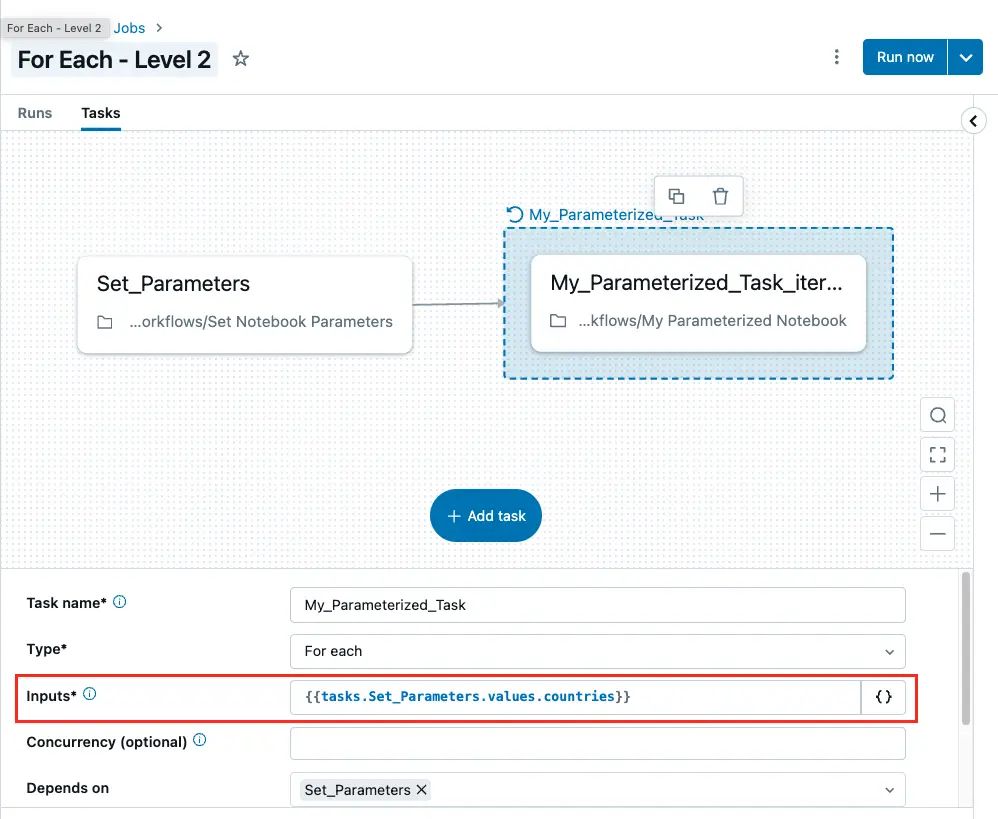 Task values set in the Set_Parameters task are accessed in the Input field
Task values set in the Set_Parameters task are accessed in the Input field
🧙♂️ Level 3: Nested For Each Loops
A logical next step would be to use nested for loops. For example, within each country we also want to loop over some of its cities. This is not natively supported in Workflows. However, as a workaround, we could use For Each to call another job. Given the input below, we would create a second job - also containing a For Each task - looping over the provided cities.
values = [
{
"country": "The Netherlands",
"cities": ["Amsterdam", "Rotterdam"]
},
{
"country": "United States",
"cities": ["New York", "Los Vegas"]
},
{
"country": "Australia",
"cities": ["Canberra", "Sydney"]
}
]
dbutils.jobs.taskValues.set(key="my_dag", value=values)
Given that this time we’ve called our task values my_dag, we create two jobs: a main job and a child job:
- The main job loops over countries, and calls another child job while passing down a list of cities.
- The child job takes the list of cities, and for each of those cities runs a parameterized notebook printing the city name.
For the main job, the input parameter for the For Each task is set to the above configuration: `` - just like for our previous Level 2 job.
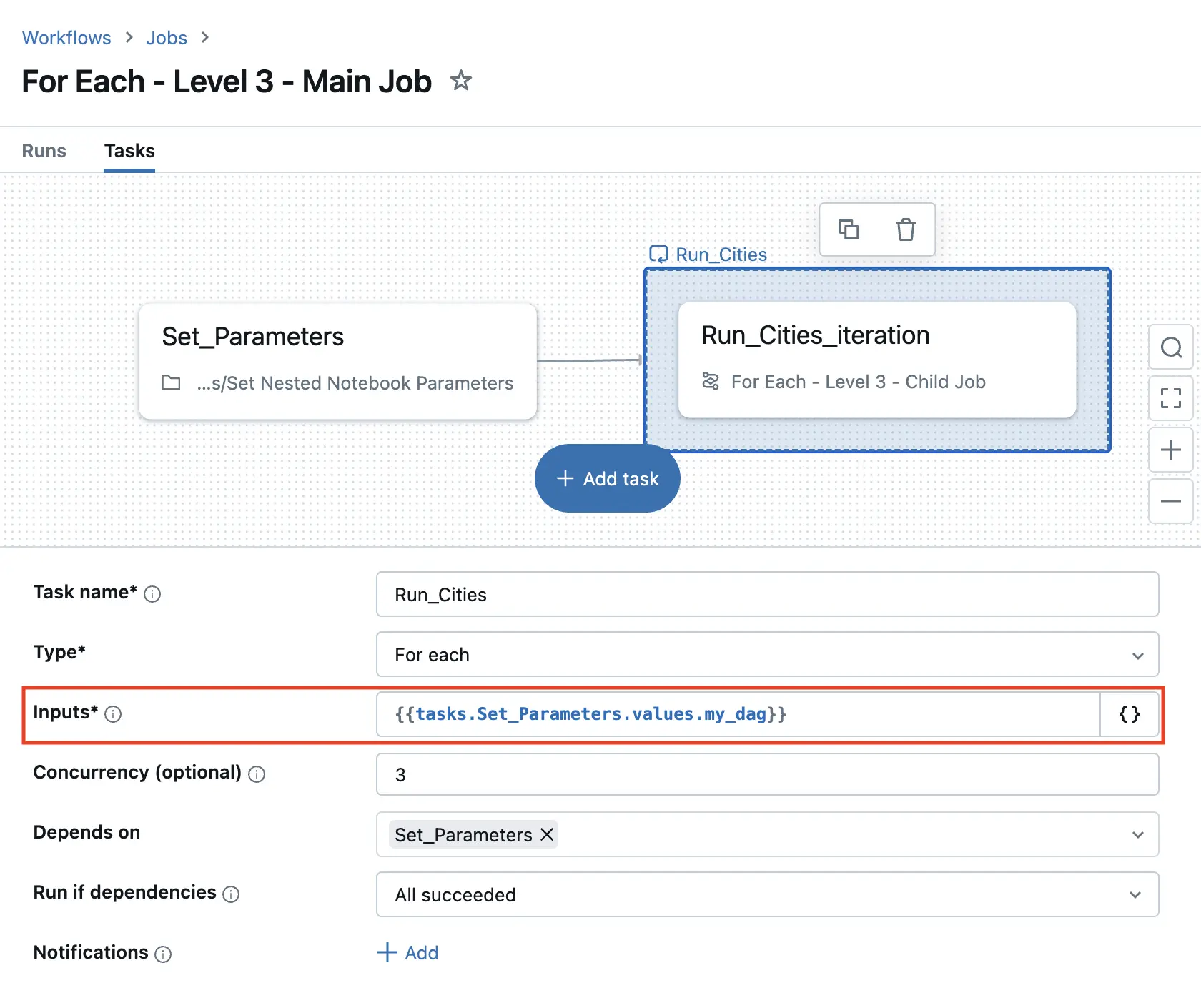 The task values set contain nested fields
The task values set contain nested fields
That way, the For Each task will loop over all dictionaries in the above configuration - one per country. However, instead of running a parameterized notebook, we call another Job that takes a list of countries as input. For good measure, we also pass the country parameter - cause why not?
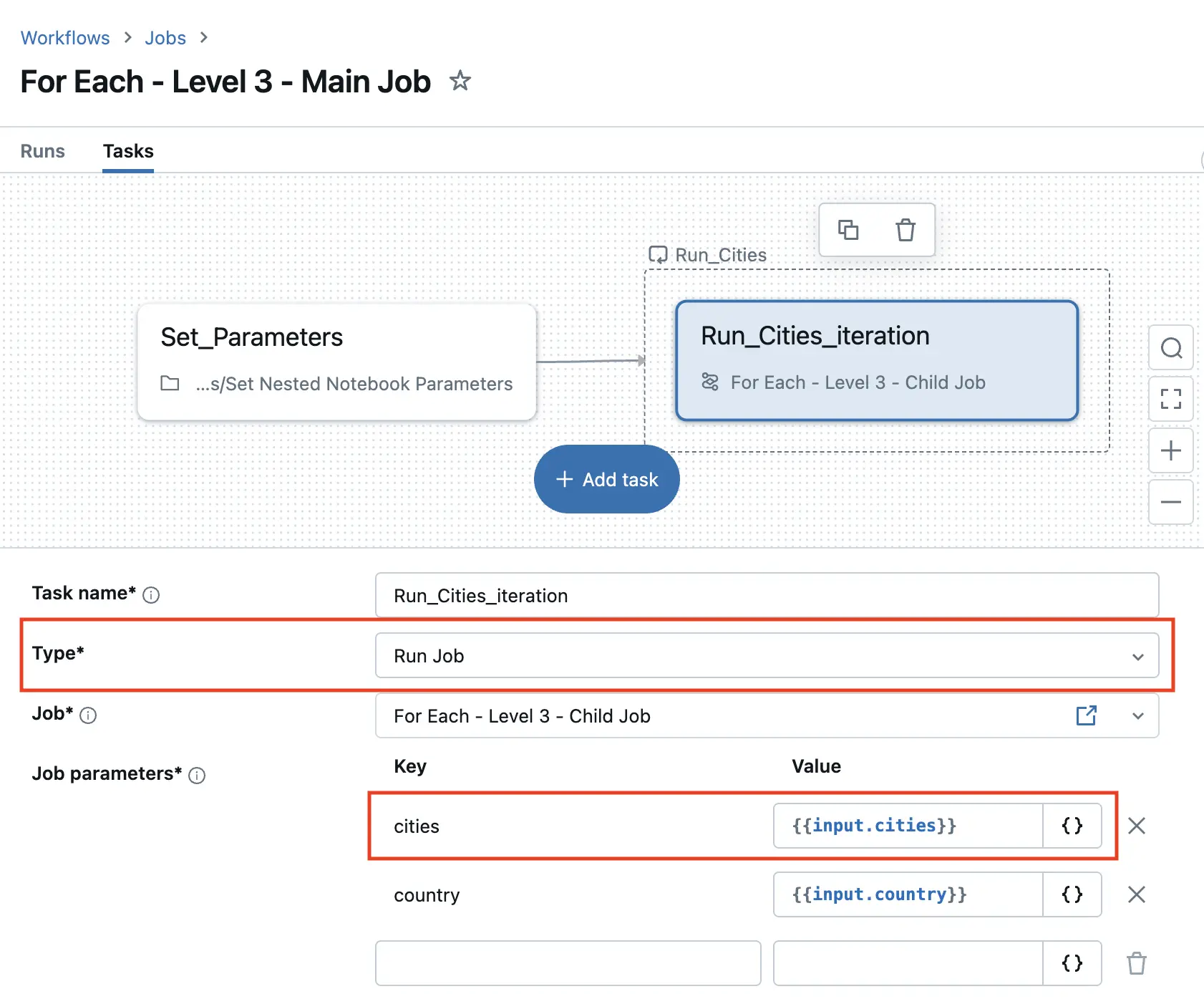 We pass the cities to the child job by setting
We pass the cities to the child job by setting citie to ``
Now all that’s left is to do is take a look at that child job that we’re calling.
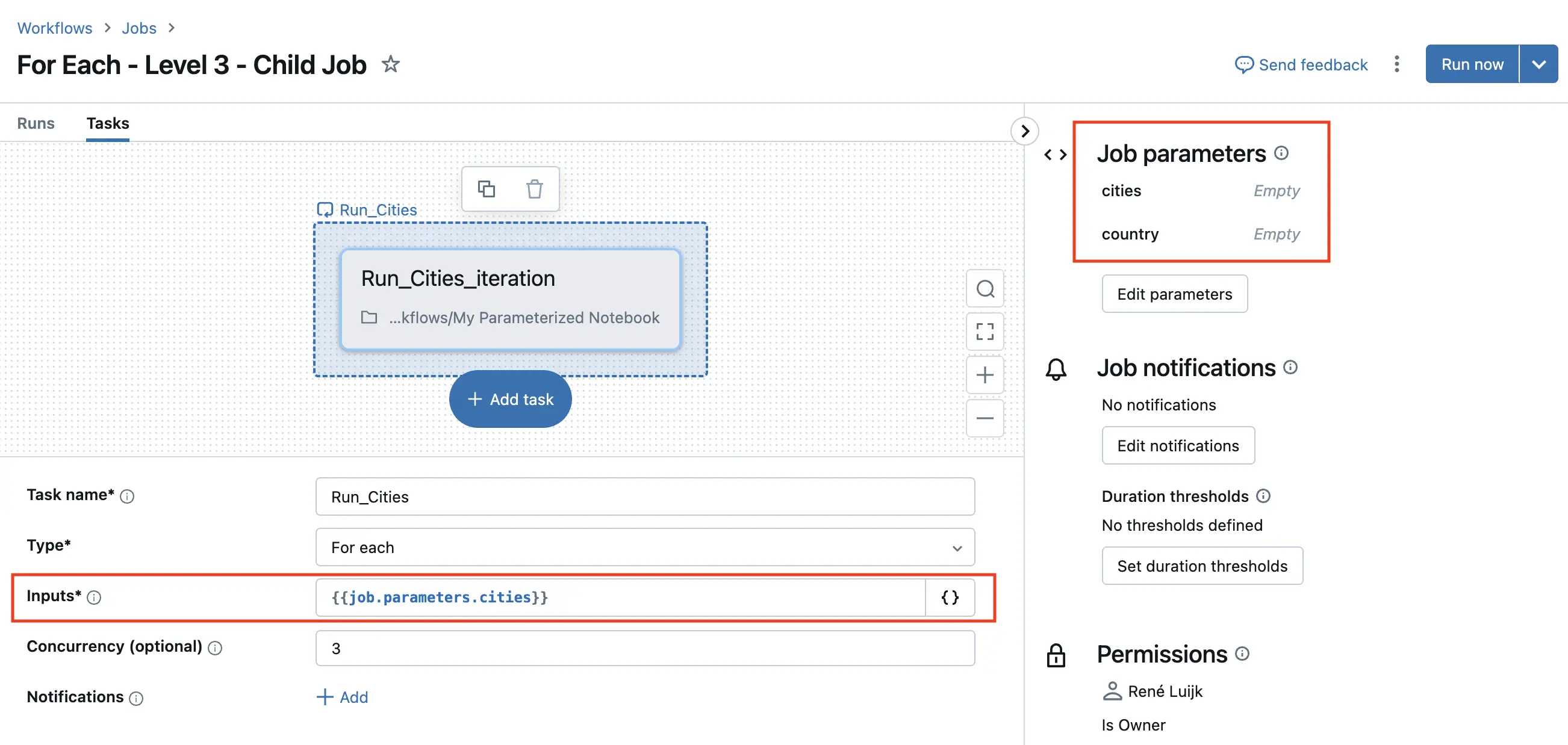 The child job is run with Job parameters
The child job is run with Job parameters
This child job takes an input parameter cities that will be populated by the main job (and country, just for good measure). The For Each task uses these job parameters as inputs: ``. Next, the For Each task runs over the cities array and runs a parameterized notebook. Voilà!
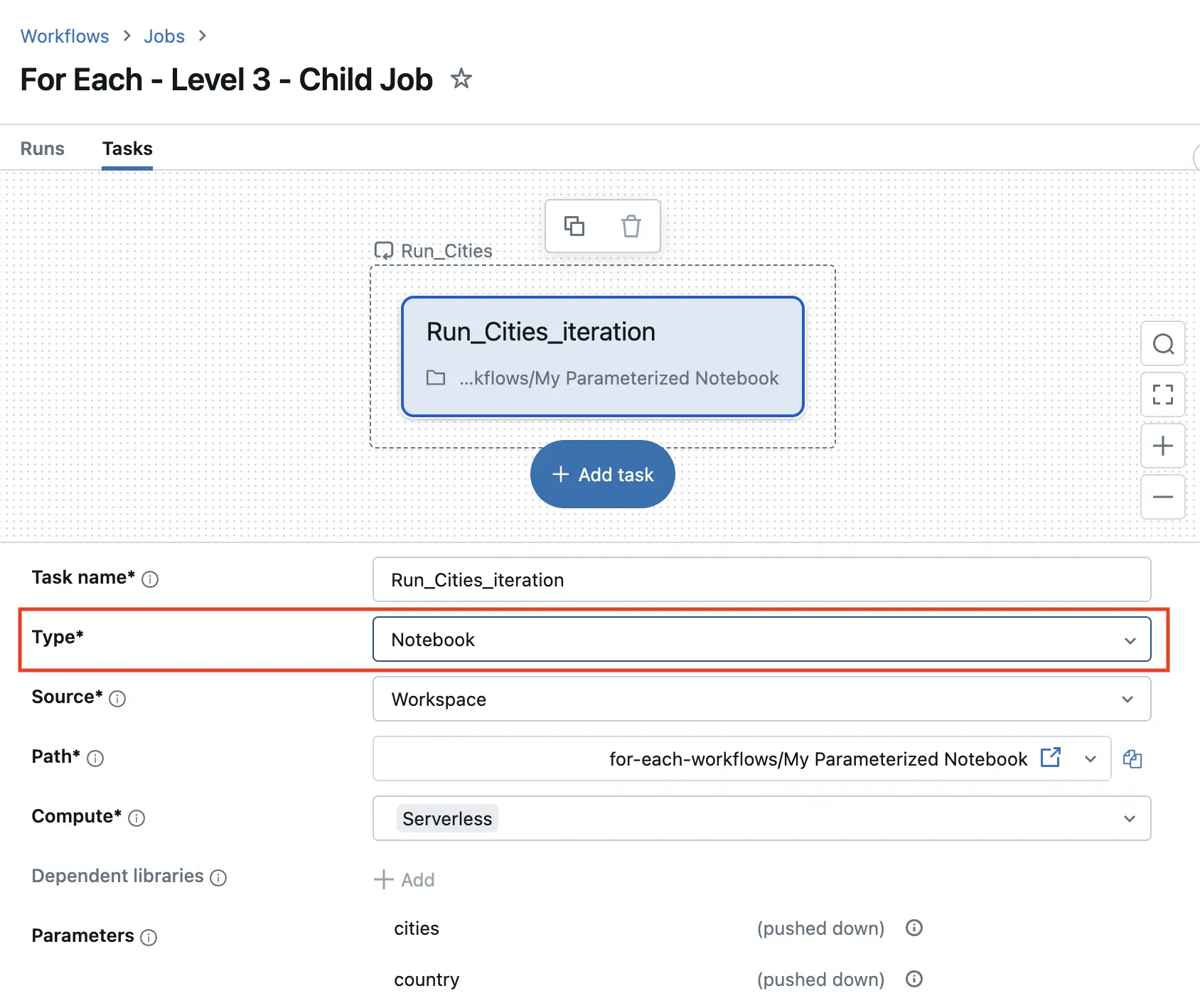 The child job loops over cities, running a parameterized notebook
The child job loops over cities, running a parameterized notebook
When you’ve gotten this far, you now truly are a wizard, Harry! 😉
Limitations And Considerations
There are several limitations and things to consider when using the For Each task type.
Single Task
For Each only allows a single task to be looped over. An orchestrator like Azure Data Factory (ADF) does allow looping over multiple tasks, which are then run in sequence. Airflow is even more flexible, and allows all kinds of customer structures - e.g., using branching.
Of course, a notebook could execute many steps, but it would have been nice to separate different steps in separate tasks.
Nested Loops
Nested loops are not supported by Workflows - nor is it by ADF. As mentioned in Level 3, a workaround is to use an outer For Each loop to call another job.
Concurrency
While not mentioned in this blog post, a concurrency parameter can be set for a For Each task - defaulting to 1. The maximum concurrency is 100, which should be plenty for most use cases. Do be mindful of how many tasks you want to run in parallel.
Running Tasks Sequentially
When the concurrency parameter is set to anything greater than the default of 1, it will run as many tasks as possible in parallel. This implies that we can also run things sequentially - just set the concurrency parameter to 1. However, in that case the order in which your tasks are executed depends on how you define the task values. Pay attention to how you define your parameters and you’re good to go.