Analyzing Apache Parquet

A Closer Look Into Apache Parquet
Several popular engineering and analytics frameworks (e.g., Delta Lake - and by extension Databricks, and Azure Synapse Analytics) use the same file format under the hood - Apache Parquet. It makes sense, as Parquet is an efficient file format suitable for large-scale analytical queries - exactly what the likes of Databricks are meant to do. However, this does not explain from a technical perspective why this makes parquet the de facto choice for these frameworks. Time to figure out what parquet is, how it works, and tie that to when parquet shines ☀️
Before we get into the nitty gritty, let’s look at what Parquet is in a nutshell. Apache Parquet is an open-source, columnar storage file format designed for efficient data processing and retrieval. It has gained widespread adoption in the big data ecosystem, including by Delta Lake. Parquet’s columnar design allows for better compression and encoding, resulting in faster query performance compared to row-based formats like Apache Avro, CSV and JSON. Its ability to handle schema evolution and its compatibility with various big data tools make it a great choice for various data workloads.
Technical Details of the Parquet Format
💾 Columnar Storage
Parquet uses columnar storage, which means the data is organized by columns rather than rows. In traditional row-based storage, data is stored sequentially row by row, where all the fields of a row are stored together. Conversely, in columnar storage, all the values of a single column are stored together.
To illustrate this difference, consider a hypothetical table employee.
| EmployeeID | Name | Age | Department |
| 1 | Alice | 30 | IT |
| 2 | Bob | 25 | IT |
| 3 | Charlie | 35 | IT |
| 4 | David | 40 | Marketing |
| 5 | Eve | 29 | Marketing |
A hypothetical table containig employee data
Row-based formats will store data per row. That way, each row contains a value for each of the four columns in our table. For the above table, this would look like this:
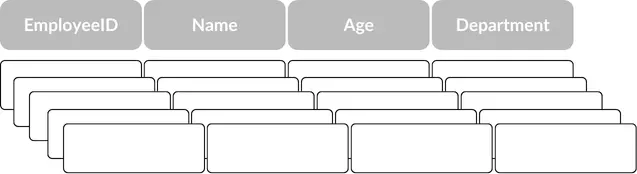 An overview of a row-based storage.
An overview of a row-based storage.
Parquet, however, uses columnar storage, meaning it stores the data for each column separately. Put differently, all values for all rows in our example table are stored together:
 An overview of a column-based storage.
An overview of a column-based storage.
Columnar storage brings with it a set of unique advantages over row-based storage, including selective column selection - also known as column pruning, and improved data compression.
This organization is particularly advantageous for analytical queries that often require reading only a few columns from a large dataset - also known as column pruning. By storing data in columns, systems can read only the relevant columns needed for a query, which minimizes I/O operations. This leads to improved performance, especially in large-scale data processing tasks. In addition, columnar storage enhances data compression capabilities due to the homogeneity of data within each column.
🧩 Data Encoding
Parquet employs various data type-specific encoding techniques to optimize storage and improve query performance. Dictionary encoding, for example, replaces repeated occurrences of values with a unique key, significantly reducing the space needed to store frequent values.
As an example, consider dictionary encoding for our Department column:
- The original column:
[IT, IT, IT, Marketing, Marketing] - Dictionary encoding
- Dictionary:
{0: IT, 1: Marketing} - Encoded column:
[0, 0, 0, 1, 1]
- Dictionary:
In this case, the Department values are replaced with integer codes, significantly reducing the amount of space needed to store the data. This is especially true when there are many repeated values.
While general-purpose encoding techniques do exist that can handle multiple data types - suitable for row-based storage formats, they are not as efficient as specific encoding techniques for a certain data type.
💪 Compression
Parquet supports multiple compression algorithms to further reduce the storage footprint and enhance read/write performance. Two of the most commonly used algorithms include Snappy and Gzip.
- Snappy. Designed for fast compression and decompression, making it ideal for real-time applications where speed is critical.
- Gzip. Provides higher compression ratios at the cost of slower performance, suitable for scenarios where storage savings are more important than speed.
🧬 Schema Evolution
Schema evolution is a feature in Parquet that allows changes to the schema of a dataset over time without requiring a complete rewrite of the existing data. For example, Parquet supports adding new columns, removing existing ones, and changing the data types of columns.
💽 Metadata
Parquet files contain rich metadata at various levels.
- File-level: the data types and structure of each column, the row count, and the Parquet version used to write the data.
- Column-level: minimum and maximum values for numeric columns,
nullcounts, distinct counts. The min/max values are used to skip reading certain rows. The latter actually is useful at the column-chunk level, but more on that later. - Footer metadata: contains a summary of the metadata needed to process the file, and the schema definition.
🧱 File Structure
Header
The Parquet file begins with a small header containing the magic number PAR1. This magic number is a constant value that identifies the file as a Parquet file.
Row Groups
A row group is a horizontal partition of the data. Each row group contains a subset of rows, and Parquet files are made up of one or more row groups. Row groups are independent of each other. This allows for independent, parallel processing, improving query performance even further. Row groups also help in optimizing I/O operations. By reading only the relevant row groups based on query filters, the system can minimize the amount of data read from disk.
Continuing our example using the employee table, we may have two row groups:
The first row group…
| EmployeeID | Name | Age | Department |
| 1 | Alice | 30 | IT |
| 2 | Bob | 25 | IT |
| 3 | Charlie | 35 | IT |
Rows corresponding to the first row group
…and the second row group.
| EmployeeID | Name | Age | Department |
| 4 | David | 40 | Marketing |
| 5 | Eve | 29 | Marketing |
Rows corresponding to the second row group
Column Chunks
Within each row group, data is stored in column chunks. Each column chunk contains the data for a specific column within a row group. As such, column chunks are the vertical partitions within row groups, and they contain the actual data values for the column they represent.
Note that the metadata mentioned earlier is stored at this column-chunk level, not at the column level. This allows for skipping certain rows, e.g., based on numeric values.
Footer
The footer contains important metadata about the file, including:
- Schema: detailed information about the data schema, including column names, data types, and hierarchical structure.
- Row group metadata: information about each row group, such as the number of rows, the byte offset, and the size of each row group.
- Column chunk metadata: statistics and encoding/compression information for each column chunk.
- Key-value metadata: arbitrary key-value pairs that can store additional custom metadata provided by the user or application.
An Example: Efficiently Querying Data Using Parquet’s File Structure
Let’s look at an example of how Parquet’s file structure is going to help us efficiently load data from the employee table defined earlier. Particularly how row groups and column chunks and their metadata improve query efficiency. First, let’s look at what the Parquet file structure might look like for our employee table.
Parquet File
├── Header (magic number "PAR1")
├── Row Group 1
│ ├── Column Chunk: EmployeeID
│ ├── Column Chunk: Name
│ ├── Column Chunk: Age
│ └── Column Chunk: Department
├── Row Group 2
│ ├── Column Chunk: EmployeeID
│ ├── Column Chunk: Name
│ ├── Column Chunk: Age
│ └── Column Chunk: Department
└── Footer
├── Metadata (schema, row group offsets, statistics, etc.)
├── Row Group Metadata
│ ├── Number of rows
│ ├── Column Chunk Statistics (min/max values, null counts, etc.)
└── Offset to Metadata
Next, suppose we want to use the following query:
SELECT Name, Department, Age
FROM employees
WHERE Age > 38 AND Department = 'Marketing';
Using this query, the following steps will be executed:
- Step 1: read file metadata
- The query engine reads the footer to access the file metadata, which includes schema information, row group offsets, and column chunk statistics.
- Step 2: evaluate row group statistics
- The query engine evaluates the statistics for the
AgeandDepartmentcolumns in each row group to determine which row groups might contain relevant data. - The
Agecolumn in row group 1 contains min/max values of 25 and 30. In row group 2 the min/max values are 29 and 40. - The distinct values in the
Departmentcolumn only containITfor row group 1, and onlyMarketingfor row group 2.
- The query engine evaluates the statistics for the
- Step 3: select relevant row group(s)
- Based on the above metadata, only row group 2 will be included.
- Step 4: read relevant column chunk(s)
- Within the selected row group, the query engine reads only the relevant column chunks:
Name,Department, andAge. - This column pruning reduces the amount of data read from disk, as the
EmployeeIDcolumn is skipped.
- Within the selected row group, the query engine reads only the relevant column chunks:
- Step 5: apply filters and return results
- The query engine applies the filter
Age > 40 AND Department = 'Marketing'to the data read from the relevant column chunks. - Rows that meet the criteria are selected, and the required columns (
Name,Department,Age) are returned.
- The query engine applies the filter
The result? The following single row with only three columns selected. Now that’s efficiency!
| Name | Age | Department |
| David | 40 | Marketing |
Result of the query
Closing Thoughts and Extending Parquet
Given Apache Parquet’s columnar storage, efficient encoding, and robust schema management, it’s no wonder that is an often-used file format for large-scale data storage and efficient querying. This includes being used by Delta Lake, which adds an extra layer on top of Parquet, even further increasing its performance and scalability.
However, that’s beyond the scope of this post. For more on Parquet and Delta Lake, stay tuned 😉