Going Gold! Using the Medallion Architecture on Databricks
An Ask Databricks Q&A on getting started with the Medallion architecture
Last call! 🔔 This is the final video in the Ask Databricks series of the season by Advancing Analytics. Today’s topic: the Medallion architecture. There’s a lot more to this deceivingly simple view on data and data quality than meets the eye.
Let’s dive in one more time! 🐬
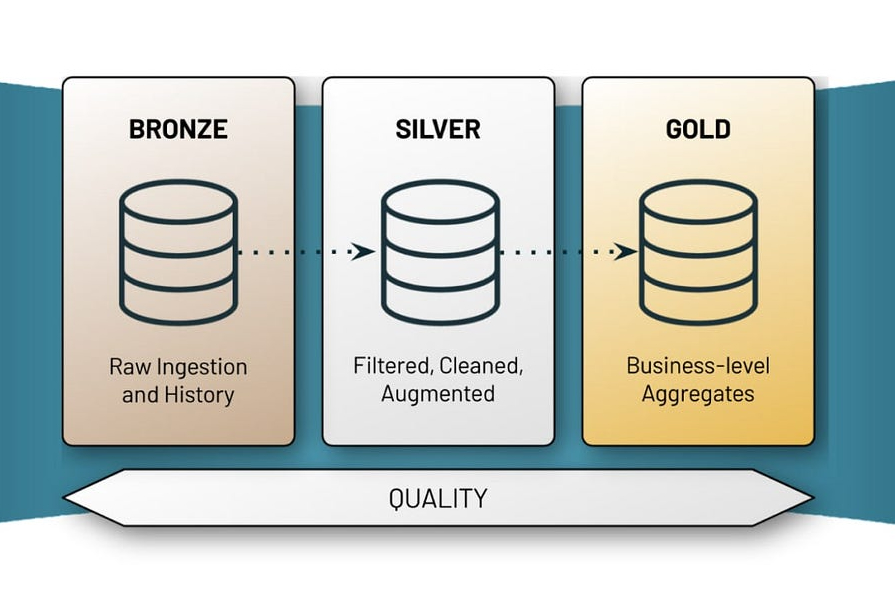
🌎 Where does Medallion come from?
The Medallion architecture in Databricks originates from the evolution of traditional data warehousing concepts, such as raw, staging, and presentation layers. In the early days of Delta, a customer introduced the terminology of bronze, silver, and gold to represent different stages of data refinement. This conceptual framework, although not strictly defined, gained popularity for its simplicity in understanding data processing stages—from raw data to refined and production-ready. Over time, vendors have even introduced a “diamond layer” to represent a semantic layer, highlighting the continuous evolution of data processing concepts. Ultimately, Medallion serves as a conceptual guide for organizing and refining data within the Databricks platform.
🥉 Medallion vs Tin and PreBronze
In comparing Medallion to Tin and PreBronze, it’s crucial to recognize the distinct approach Medallion takes in data governance. While other frameworks may use terms like bronze, silver, and gold, Medallion’s architecture diverges from traditional data governance tiers. The emphasis is on contextual understanding rather than rigid classifications. For instance, a business user preparing their own data may fall under the silver level in Medallion, denoting a curated, business-ready state, albeit not adhering to formal production standards. The key takeaway is that regardless of the nomenclature, the focus is on providing context to data consumers, ensuring they comprehend the source and quality of the data within the lake or platform.
🏗️ How to set up Delta Tables
Setting up Delta tables in Databricks involves a thoughtful approach to data modeling, especially as Delta has evolved. Initially, in the early Lake days, you could materialize Delta tables directly from the data frame. However, with advancements like additional table properties, identity columns, foreign keys, and primary keys, the process has become more nuanced. Now, it’s crucial to consider defining Delta tables upfront, taking into account properties and dynamics. This strategic thinking ensures a more efficient and scalable setup, avoiding the need to add new racks for scaling, a significant improvement over past data warehouse appliance challenges.
🎯 Defining Delta Tables
The key innovation lies in the concept of Delta Live Tables, which fundamentally changes how tables are defined and managed. Unlike traditional data warehousing, where schema definition upfront can be rigid and inflexible, Delta Live Tables allow for dynamic schema evolution at runtime. This means you no longer need to issue create table statements; instead, the system interprets the schema based on the select statement, creating tables on the fly. The flexibility extends to handling changes in business requirements, accommodating new columns seamlessly with schema evolution or merge schema capabilities. This approach significantly reduces the challenges associated with fixed schemas, making it more adaptable to the changing dynamics of business. Whether you choose to define tables upfront or create them dynamically, Delta Live Tables provide a versatile solution that minimizes the complexity of schema management, offering a pragmatic and efficient approach for both migration and new projects in the Lakehouse paradigm.
🧬 Schema evolution
Embracing schema evolution at the early stages of the Lakehouse process is crucial. While initially aligning with the idea of letting data define schemas and evolve naturally, there could be value in having a deliberately designed gold layer with structured data models. This approach, initially complemented by views and Databricks SQL tables, became more essential as Delta introduced features tied to table properties, constraints, identity columns, and surrogate keys. Balancing the flexibility of schema evolution with the need for a well-defined data model, having more free flowing bronze and silver layers with a well-structured gold layer seems useful. This method ensures a purposeful design from the outset, avoiding the challenges of retroactively fitting data models to existing streams, ultimately enhancing the efficiency and clarity of the data architecture.
⭐ Star Schema or Vault
When deciding between a Star Schema or Data Vault architecture in Databricks, it ultimately depends on your specific use case and requirements. However, considering the ETL side, the insert-only architecture of Data Vault, especially in an Object Store, appears more efficient due to its adaptability to change over time, particularly in the context of the Lakehouse architecture. Ultimately, the choice should align with the comfort and expertise of the data expert, allowing for gradual optimization and adaptation over time in the Lakehouse environment.
📦 Data Vault
The primary argument in favor of the Data Vault revolves around its scalability to handle complex change management processes. This is particularly true in the context of large organizations like banks with numerous systems. While acknowledging that simpler solutions like the Star schema work well for small companies with straightforward data and business requirements, a Data Vault becomes invaluable when dealing with the challenges of conforming data from multiple source systems in large, acquired organizations. The key takeaway is that the choice between architectures depends on the specific needs and scale of the organization.
🪺 Nested data
In the Medallion Architecture within Databricks, handling nested data requires thoughtful consideration. While some organizations unnest nested structures early in the process (often at the Silver level), others choose to keep them until the Gold level, leveraging Databricks’ capabilities with structs and arrays. The approach to unnesting can impact storage costs, and a more sophisticated method involves treating nesting as a join to another table. Silver is commonly the stage where unnesting occurs, providing role-level detail.
💡 Analytics Philosophy
In the realm of analytics, there are two prevailing philosophies when dealing with data quality in the context of creating data models and dashboards. On the one hand, some argue for displaying the absolute truth of the data, emphasizing the importance of transparency and accountability for poor data quality at the source system. On the other hand, there’s a perspective that sees the analytics person as the guardian, responsible for presenting only clean and solid business data, shielding the business from the intricacies of dirty data. The choice between these approaches hinges on the data culture in play. It’s not a matter of a one-size-fits-all solution, but rather a nuanced decision influenced by the specific dynamics of each organization.
⛑️ Data ownership and data quality
In the context of the Medallion Architecture in Databricks, addressing data ownership is crucial, particularly in regulated industries. Depending on the business goals, there’s a delicate balance between revealing the true state of the data, even if it’s problematic, and withholding it to avoid immediate consequences. It must be noted, however, that showcasing the data’s flaws often acts as a catalyst for businesses to take ownership and proactively address data quality issues. The goal is to encourage a shift towards businesses actively owning their data products and fostering a culture of responsibility for the overall data quality. Simply tweaking reports doesn’t solve the root cause. As data professionals, it’s important to resist the urge to patch reports and instead focus on maintaining data integrity from the source system. This approach ensures accurate and reliable insights for decision-making.