How To Prepare For The Databricks Spark Developer Associate Certification

A full overview of the course material
So you’re looking to get that Spark Developer Associate certification? As part of my own preparation for the exam, I’ve written a short description for each of the (high-level) topics that are mentioned at the end of the Databricks course, so you don’t have to. 😉
The exam consists of 60 questions, and covers three main topics:
- Apache Spark Architecture Concepts (17%)
- Apache Spark Architecture Applications (11%)
- Apache Spark DataFrame API Applications (72%)
Covering 72% of all questions, the DataFrame API is the most important. Unfortunately, this is also the section that will require the most hand-on experience. So unless you’re like that one lawyer in the series Suits (Michael Ross), and you can memorize the entire documentation word for word, you’ll need to get your hands dirty. Just a fair warning.
There’s a lot of material to cover, so let’s get going!
- Apache Spark Architecture Concepts (17%)
- Apache Spark Architecture Applications (11%)
- Apache Spark DataFrame API Applications (72%)
Apache Spark Architecture Concepts (17%)
Clusters
A Spark cluster is a distributed computing environment that consists of multiple interconnected machines, enabling the parallel processing of large-scale data using Apache Spark, a fast and general-purpose cluster computing system. An overview of its components:
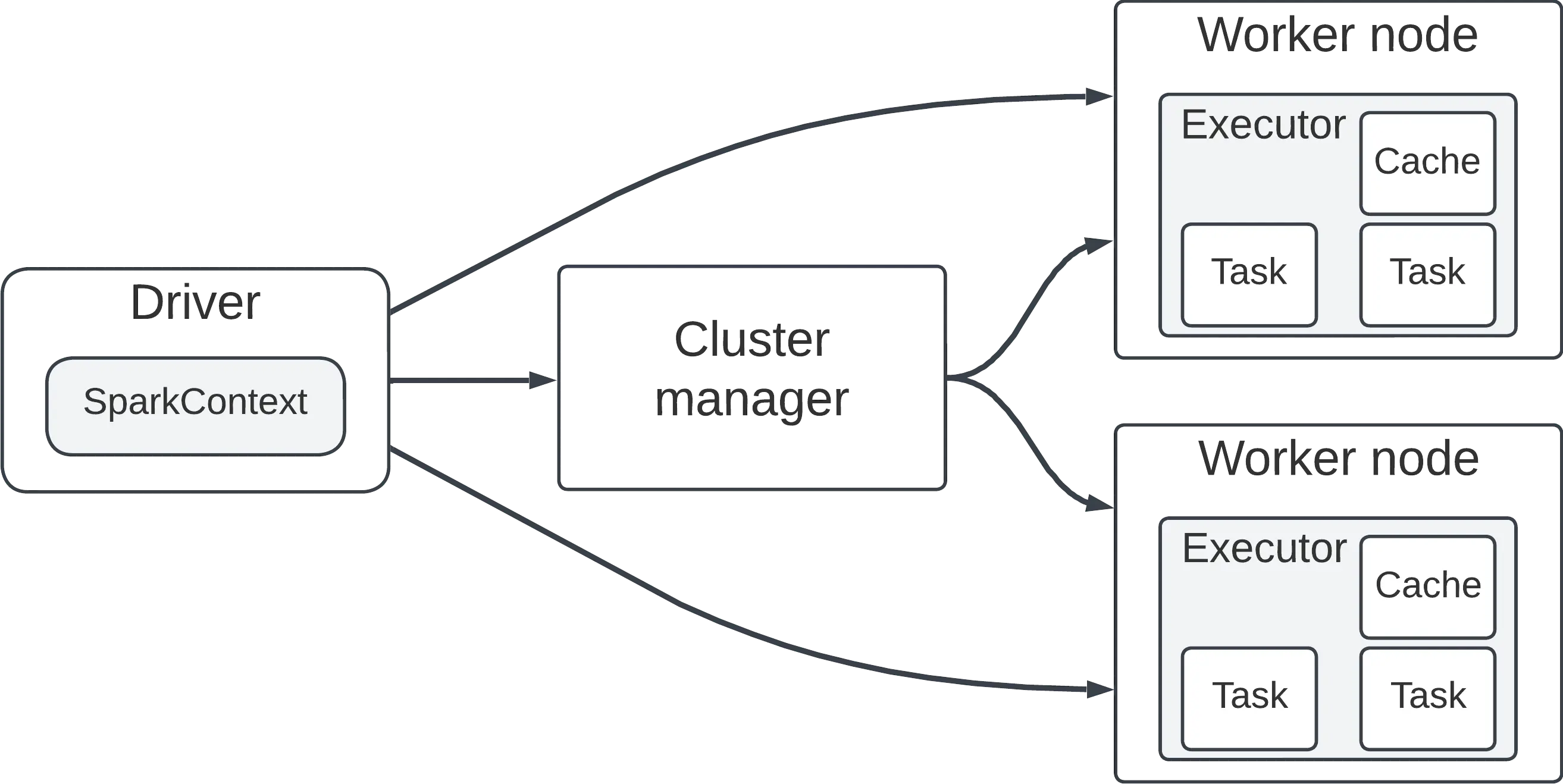
Nodes
- Driver nodes: The driver node is the entry point for a Spark application. It runs the
mainfunction and creates theSparkContext, coordinating the distribution of tasks across worker nodes. - Worker nodes: Worker nodes are responsible for executing tasks assigned by the driver. They store data and perform computations.
Executors
- Relationship with worker nodes: Executors are processes launched on worker nodes to run Spark tasks. Each worker node can have multiple executors.
- Relationship with the JVM: Each executor runs within a Java Virtual Machine (JVM), isolating tasks and providing fault tolerance.
Slots
- Description: A slot is a basic unit of parallelism in Spark. It represents the computational capacity of an executor to execute a single task.
- Purpose: Slots allow multiple tasks to run concurrently on a single executor, maximizing parallelism and resource utilization.
Execution Hierarchy
The Spark execution hierarchy consists of a Spark application containing multiple jobs, each job comprising stages, and each stage composed of tasks, representing the fundamental unit of parallel execution in the Spark computing framework.
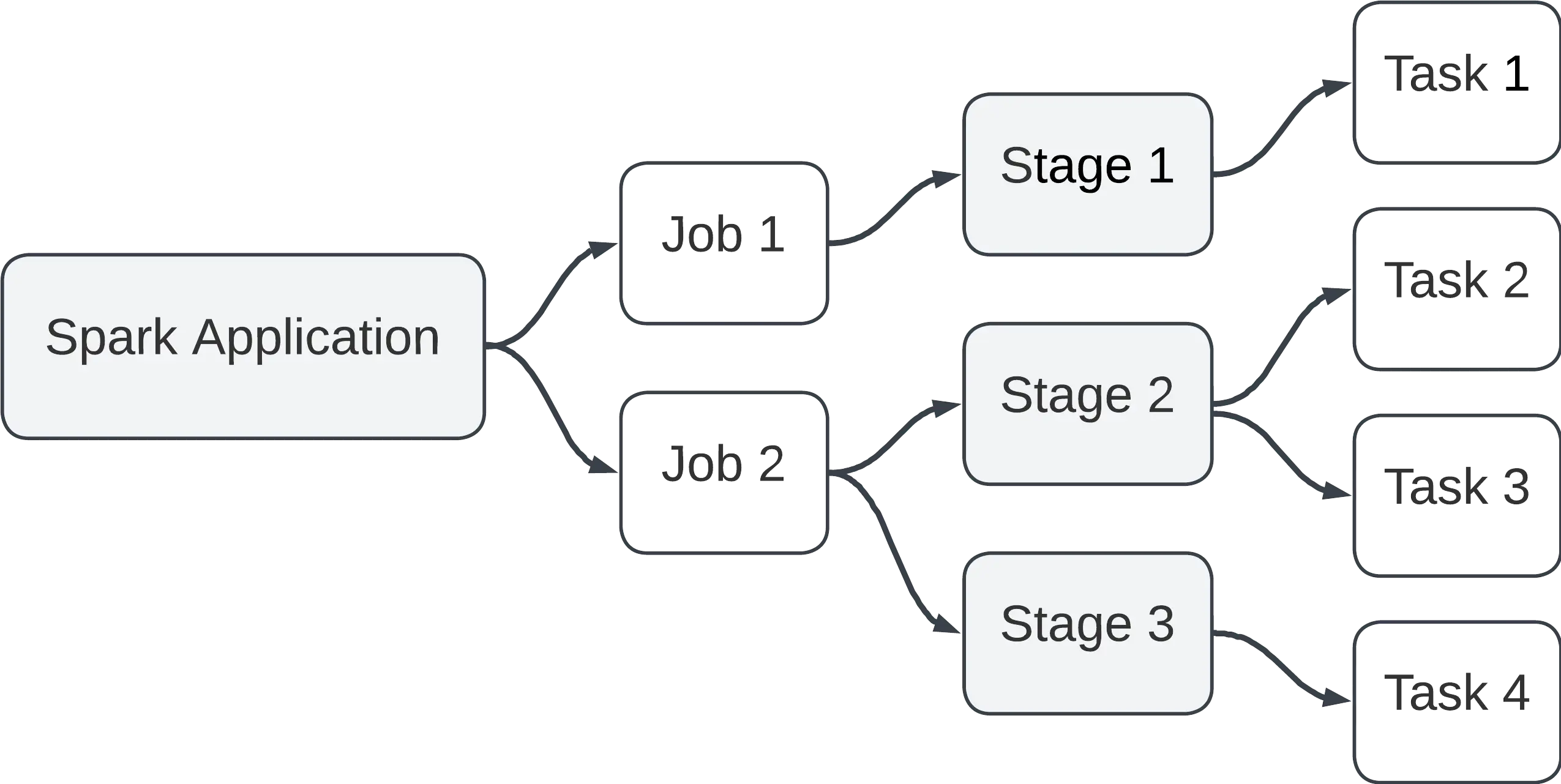
Application
- Description of a Spark application: A Spark application is a self-contained computation, consisting of a driver program and a set of parallelized tasks executed on a cluster.
Jobs
- Description of Spark Jobs: A job is a Spark application’s high-level unit of work. It consists of stages, and it is initiated by an action triggered in the driver program.
Stages
- Description of Spark stages: A stage is a set of tasks that can be executed in parallel without data shuffling. Stages are determined by transformations that have narrow dependencies.
- Identify what separates a Job into multiple stages: A job is divided into stages at the boundaries where data needs to be shuffled between partitions.
Tasks
- Description of Spark Tasks: A task is the smallest unit of work in Spark, representing the execution of a single operation on a partition of data.
Distribution
Shuffles
- Description of shuffling: Shuffling is the process of redistributing data across the partitions, often involving data exchange between nodes. It can be a costly operation.
- Operations that result in a shuffle: Operations like
groupByKey,reduceByKey, andjoinresult in shuffling. - Configuration prone to a lot of shuffling: Setting a high level of parallelism or having a small number of partitions can lead to increased shuffling.
Partitions
- Description of partitions: Partitions are basic units of data parallelism in Spark. Each partition holds a subset of the data, and tasks operate on partitions independently.
- Configurations that affect partitioning: The number of partitions is affected by configurations like
spark.default.parallelismand can be controlled during operations likerepartition.
Execution Patterns
Lazy Evaluation
- Description of Lazy Evaluation: Lazy evaluation is a strategy where transformations on RDDs are not immediately executed. Instead, they are recorded, and the execution is deferred until an action is called.
- Advantages: It minimizes unnecessary computations, optimizes execution plans, and improves performance.
- Operations that trigger evaluation: Actions like
count,collect, andsaveAsTextFiletrigger the evaluation of transformations.
Transformations
- Description of transformations: Transformations are operations that create a new RDD from an existing one. They are lazily evaluated.
- Narrow vs. wide transformations: Narrow transformations (e.g.,
map) do not require data shuffling, while wide transformations (e.g.,groupByKey) do involve shuffling.
Actions
- Description of actions: Actions are operations that trigger the execution of transformations and return a result to the driver program or write data to an external storage system.
- Operations that are actions: Examples include
count,collect,saveAsTextFile, andreduce.
Apache Spark Architecture Applications (11%)
Clusters
Execution and Deployment Modes
- Purpose of driver and executor setup: The driver program is responsible for coordinating the Spark application, while executors are responsible for task execution. The setup ensures the distribution and parallel processing of tasks.
- Types of deployment modes:
- Cluster mode: Driver and executors run on the cluster.
- Client mode: Driver runs on the client machine, connecting to executors on the cluster.
- Local mode: Both driver and executors run on the local machine for development and testing.
Fault Tolerance and Stability
- Reasons a Spark application will fail: Network issues, hardware failures, and application bugs can lead to failures.
- Fault-tolerant cluster setups: Spark provides fault tolerance through lineage information and recomputing lost data. Configurations like replication factor and checkpointing enhance fault tolerance.
Storage
Caching
- How Spark caches data: Spark caches data in memory, reducing recomputation by storing computed results.
- When to cache
DataFrames: CacheDataFrameswhen they are reused, reducing computation time.
Storage Levels
- Types of storage level: a link to the documentation would be easiest 😉
- Default storage level:
MEMORY_ONLYWhen to use each storage level: Choose based on memory constraints and computation needs.
Out-of-memory Errors
- Why out-of-memory errors occur: Large datasets or inefficient transformations can exceed available memory.
- Strategies for reducing out-of-memory errors: Increase cluster size, optimize code, or use storage levels to spill to disk.
Garbage Collection
- Purpose: To reclaim memory occupied by objects that are no longer in use.
- Efficient garbage collection configurations: Configure garbage collection settings based on memory requirements, considering options like G1GC.
Partitioning
Repartitioning
- How to repartition a
DataFrame: Use therepartitionmethod to increase or decrease the number of partitions.
Coalescing
- How to coalesce a
DataFrame: Use thecoalescemethod to reduce the number of partitions without shuffling. - Relationship with repartitioning a
DataFrame: Coalescing is a more efficient operation when reducing partitions, as it avoids full shuffling.
Data Skew
- Describe data skew: Data skew occurs when certain partitions have significantly more data than others, leading to uneven processing.
- General strategies for avoiding data skew: Preprocess data to distribute keys evenly, use salting techniques, or leverage specific join strategies.
AQE Skew Handling
- Configurations needed for automatic skew handling: Adaptive Query Execution (AQE) automatically handles skew. No specific configurations are required.
Structures (DataFrame)
Basics
- Description of Spark
DataFrames:DataFramesare distributed collections of data organized into named columns, providing a higher-level abstraction than RDDs. - Spark class used as the base for
DataFrames:org.apache.spark.sql.DataFrame
Types and Execution
- Possible column types: many exist, see the documentation.
- Parallel execution: DataFrames support parallel execution, enabling distributed data processing.
Broadcasting
Variables
- How to broadcast a variable: Use the
broadcastfunction to mark a variable for broadcasting. - What it means to
broadcasta variable: Broadcasting a variable means sharing it efficiently across all nodes to reduce data transfer overhead.
Joins
- Configurations for automatic broadcast joins: Set
spark.sql.autoBroadcastJoinThresholdto determine the size threshold for automatic broadcast joins. - When broadcast joins are advantageous: Broadcast joins are beneficial when one side of the join is small enough to fit in memory.
Adaptive Query Execution (AQE)
- Adaptive Query Execution (AQE) is an optimization technique in Spark SQL that makes use of the runtime statistics to choose the most efficient query execution plan.
- How to set up Spark to automatically handle broadcast joins using AQE: AQE automatically handles broadcast joins without specific setup, improving performance.
Apache Spark DataFrame API Applications (72%)
Columns
Subsetting
- Select columns from a DataFrame: Use the
selectmethod to choose specific columns. - Drop columns from a DataFrame: Use the
dropmethod to remove unwanted columns.
Renaming
- Rename existing columns: Utilize the
withColumnRenamedmethod to rename columns.
Manipulating
- Cast column types: Use the
castmethod to convert a column to a different data type. - Create a constant column: Use the
litfunction to add a new column with a constant value. - Split an existing string column: Employ the
splitfunction to divide a string column into multiple columns. - Explode an array column: Use the
explodefunction to transform array elements into separate rows. - Date manipulations: Use functions like
date_add,datediff, andtruncfor date manipulations.
Rows
Filtering
- Single-condition filtering: Use the
filterorwheremethod for basic filtering. - Multiple-condition filtering: Combine multiple conditions using logical operators (
&,|,~).
Dropping
- Dropping duplicates: Use the
dropDuplicates(ordrop_duplicates) method to remove duplicate rows. - Sampling: Utilize the
samplemethod to create a random sample of the DataFrame.
Sorting
- Order by one column: Use the
orderByorsortmethods to sort theDataFrameby one or more columns. - Change column order: Select columns in a different order to change the column arrangement.
Aggregating
- Summary descriptions: Use functions like
describeorsummaryfor summary statistics. - Single-/multi-column aggregations: Utilize functions like
sum,avg, andmaxfor single or multiple column aggregations. - Grouped aggregations: Use the
groupBymethod to perform aggregations on specific groups.
Miscellaneous
Combining data
- Joins: Use methods like
jointo combine DataFrames based on common columns. For more details on the types ofjoins, see the documentation. - Broadcast joins: Optimize small-table joins using
broadcastjoins. - Unions: Use
unionorunionByNameto combineDataFramesvertically.
I/O
- Reading and writing: Use
readandwritemethods to read from and write to various data sources. - Write by partitions: Improve write performance by specifying the number of partitions.
- Read schemas: Provide schema information when reading data.
- Persist/caching: Use
persistorcacheto persistDataFramesin memory for faster access.
Partitioning
- Coalescing: Use the
coalescemethod to reduce (only reduce!) the number of partitions without shuffling. - Repartitioning: Use the
repartitionmethod to either increase or decrease the number of partitions.
Custom Functions
Python UDFs
- Create Python UDFs: Use the
udffunction to define a Python UDF. - Create Pandas UDFs: Use the
pandas_udfdecorator to create Pandas UDFs. - Execution of Python and Pandas UDFs: Apply UDFs using the
withColumnmethod.
Scala UDFs
- Create Scala UDFs: Register Scala UDFs using the
udffunction. - Execute Scala UDFs: Apply Scala UDFs using the
withColumnmethod.
Spark SQL Execution
- Execute a SQL query: Use the
spark.sqlmethod to execute SQL queries on DataFrames.