A plethora of tools exist to create data pipelines. Every major player in the cloud computing business provides one (Azure Data Factory,AWS Glue, Google Cloud Composer, Databricks Workflows), though various open-source alternatives exist as well (e.g.,Airflow, Airbyte, or Prefect. Though they’re open source, fully managed versions of these do exist (e.g.,Astronomer provides a managed version of Airflow called Astro). Previously, I’ve had enjoyable experiences building pipelines with Airflow (self-hosted), Databricks Workflows, and Delta Live Tables (though not really an orchestrator).
I was once asked a simple question during a job interview: “what constitutes data quality?” Surely that must have been an easy question to answer. After all, we all have a gut feeling of what quality data is. Or at least most of us will have a sense of what bad data looks like. And yet it stumped me. Why was I unable to just give a comprehensive and cohesive answer?
How to effectively use Apply Changes for Change Data Capture
In SQL, the MERGE statement is a familiar tool in the toolkit of any data specialist, frequently employed for managing Change Data Capture (CDC). Unsurprisingly, the power of MERGE INTO extends into the Databricks environment. However, the use of MERGE for CDC data presents its own set of challenges.
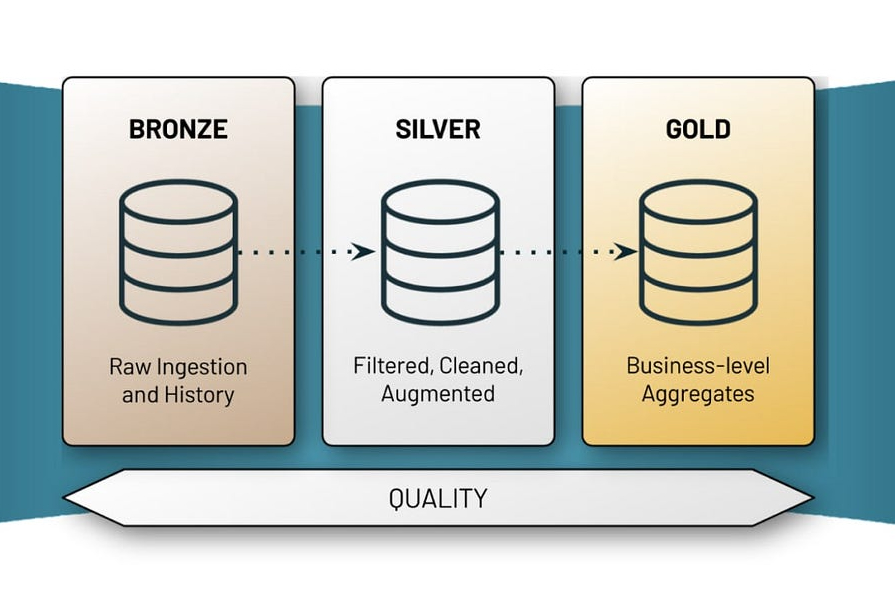
An Ask Databricks Q&A on getting started with the Medallion architecture
Last call! 🔔 This is the final video in the Ask Databricks series of the season by Advancing Analytics. Today’s topic: the Medallion architecture. There’s a lot more to this deceivingly simple view on data and data quality than meets the eye.
So you’re looking to get that Spark Developer Associate certification? As part of my own preparation for the exam, I’ve written a short description for each of the (high-level) topics that are mentioned at the end of the Databricks course, so you don’t have to. 😉